Following up my earlier post on using GPT-4o for web scraping (and finding out how expensive it is!), I wanted to investigate approaches to lower the cost.
My hypothesis was that the document’s structure would have an important effect when trying to extract structured data and that I’d see an important cost vs. accuracy trade-off: by stripping out structure from the HTML document, I was expecting an important degradation in accuracy but this turned out to be false: GPT-4o doesn’t need any HTML structure to correctly extract data.
I used the Mercury Prize Wikipedia page as input data; this page has a reasonable size and it contains a long table with multiple entities (years, artists, albums, nominees), but most importantly, it’s a fun dataset to work with.
Experimental setup: questions
Since I wanted to test to what extent the HTML structure would have an effect on extraction quality, I asked GPT-4o two types of questions:
- Unstructured: the information to correctly answer is included in the document’s paragraphs and the answer is a string
- Structured: the information to correctly answer is included in the table and the answer is structured (a list of strings)
I asked 20 questions in total, 10 unstructured and 10 structured.
I varied the complexity of the questions. For the unstructured case it was pretty limited since there isn’t much wiggle room and I didn’t want to ask questions that involved math (as evaluating math capabilities is not the purpose of this experiment).
However, the structured case gave me more space to experiment. Here are some sample questions:
Give me the years for the 1st, 4th and 8th editions (in order)
The answer involves understanding the table structure and order.
Extract the shortlisted nominees (include the winner) for the 25th edition, only the artist names (they appear first, followed by the album)”
This answer also involves structure understanding: it first has to find the row for the 25th edition, then extract data from two columns (winner and nominees are in two separate columns) and then split data that appears in the same column (Artist - Album):
You can see all the questions in the source code.
Experimental setup: pre-processing
Next, I developed a couple of text pre-processing pipelines that transform the HTML document: the objective is to reduce the number of tokens to lower the cost (as OpenAI charges per token). I tried the following pre-processing pipelines:
- No processing: the HTML document is passed as-is to the model (the most expensive approach!)
- Clean HTML: excludes everything outside the
<body></body>tags, removes all attributes from HTML tags (exceptclass,id, anddata-testid), replacesclassandidwith increasing numbers (1, 2, 3, etc.), cleans up whitespace, and replaces<a>TEXT</a>withTEXT - HTML remover: completely removes all HTML and only keeps the text
- Converts the HTML into markdown (I added this because some people recommended it on X/Twitter - LLMs are trained with a lot of markdown, hence, they’re expected to understand their structure)
Experimental setup: prompts
Here are the functions that I used to call GPT-4o and GPT-4o mini.
Unstructured
def answer_question(*, html_content: str, model: str, query: str) -> str:
SYSTEM_PROMPT = """
You're an expert question-answering system. You're given a snippet of HTML content
and a question. You need to answer the question based on the HTML content. Your response should be a plain text answer to the question based on the HTML content. Your
answer should be concise and to the point.
"""
completion = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": SYSTEM_PROMPT.strip(),
},
{
"role": "user",
"content": f"HTML Content: {html_content}\n\nQuestion: {query}",
},
],
)
return completion.choices[0].message.content
Structured
class ParsedColumn(BaseModel):
name: str
values: List[str]
def parse_column(*, html_content: str, model: str, query: str) -> dict:
SYSTEM_PROMPT = """
You're an expert web scraper. You're given the HTML contents of a table, a user
query and you have to extract a column from it that is related to the user query.
The name of the column should be the header of the column. The values should be the
text content of the cells in the column.
"""
completion = client.beta.chat.completions.parse(
model=model,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": f"HTML Content: {html_content}",
},
{
"role": "user",
"content": f"User Query: {query}",
},
],
response_format=ParsedColumn,
)
event = completion.choices[0].message.parsed
return event.model_dump()
Model evaluation
I considered answers to the Unstructured questions to be correct when they contain the answer. Let’s see a sample question:
Which artist has been nominated the most times for the Mercury Prize without winning?
Any of these is considered a correct answer:
- Radiohead
- Radiohead is the band that has been nominated the most with no wins
- The answer is Radiohead
In the Structured questions there were two cases: in some, the answer’s order did not matter, but in others, it did.
Here’s a sample question whose answer didn’t require ordering:
Extract the shortlisted artists (exclude the winner) for 2015. Only artist names (artists appear first, followed by the album)
answer = {
"Aphex Twin",
"Gaz Coombes",
"C Duncan",
"Eska",
"Florence and the Machine",
"Ghostpoet",
"Róisín Murphy",
"Slaves",
"Soak",
"Wolf Alice",
"Jamie xx",
}
assert set(answer_gpt4) == answer
Here’s an example of a question whose answer required ordering:
Extract the winners of the Mercury Prize from 1992 to 1995, in order
Expected answer:
answer = [
"Primal Scream – Screamadelica",
"Suede – Suede",
"M People – Elegant Slumming",
"Portishead – Dummy",
]
assert answer_gpt4 == answer
Results
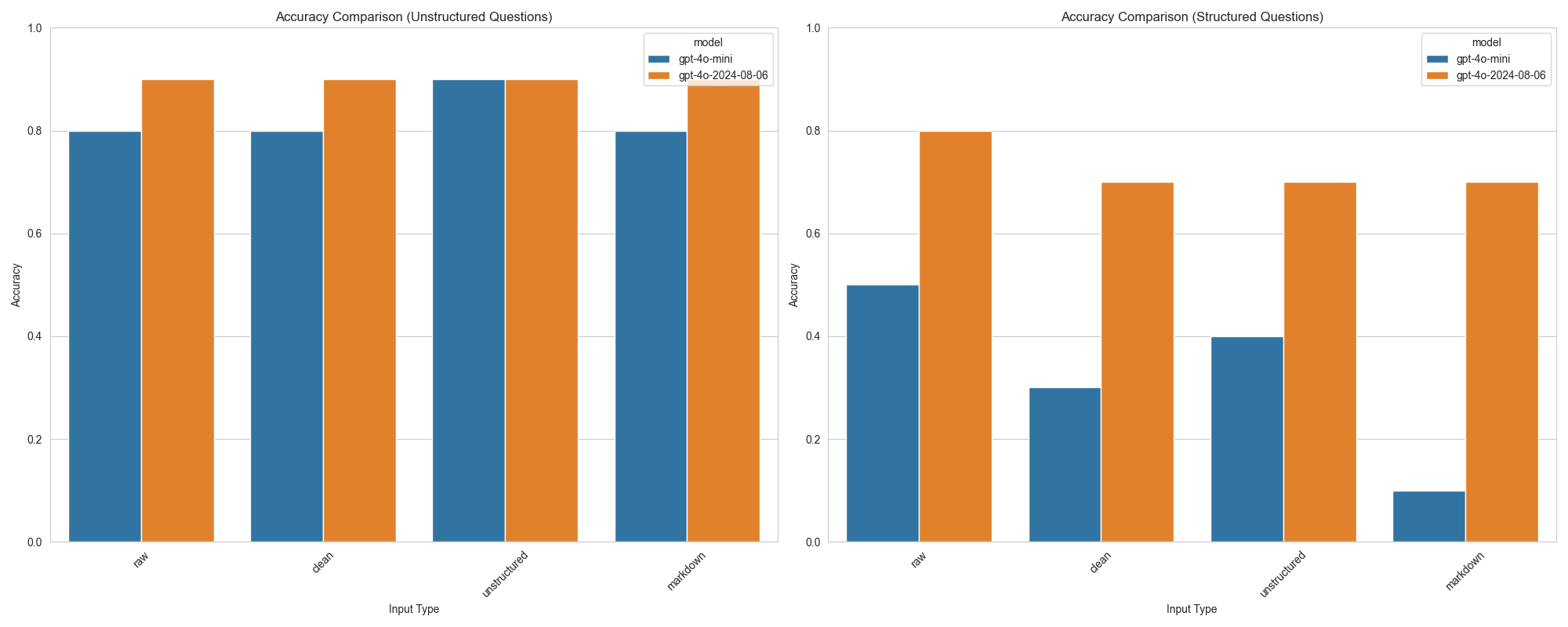
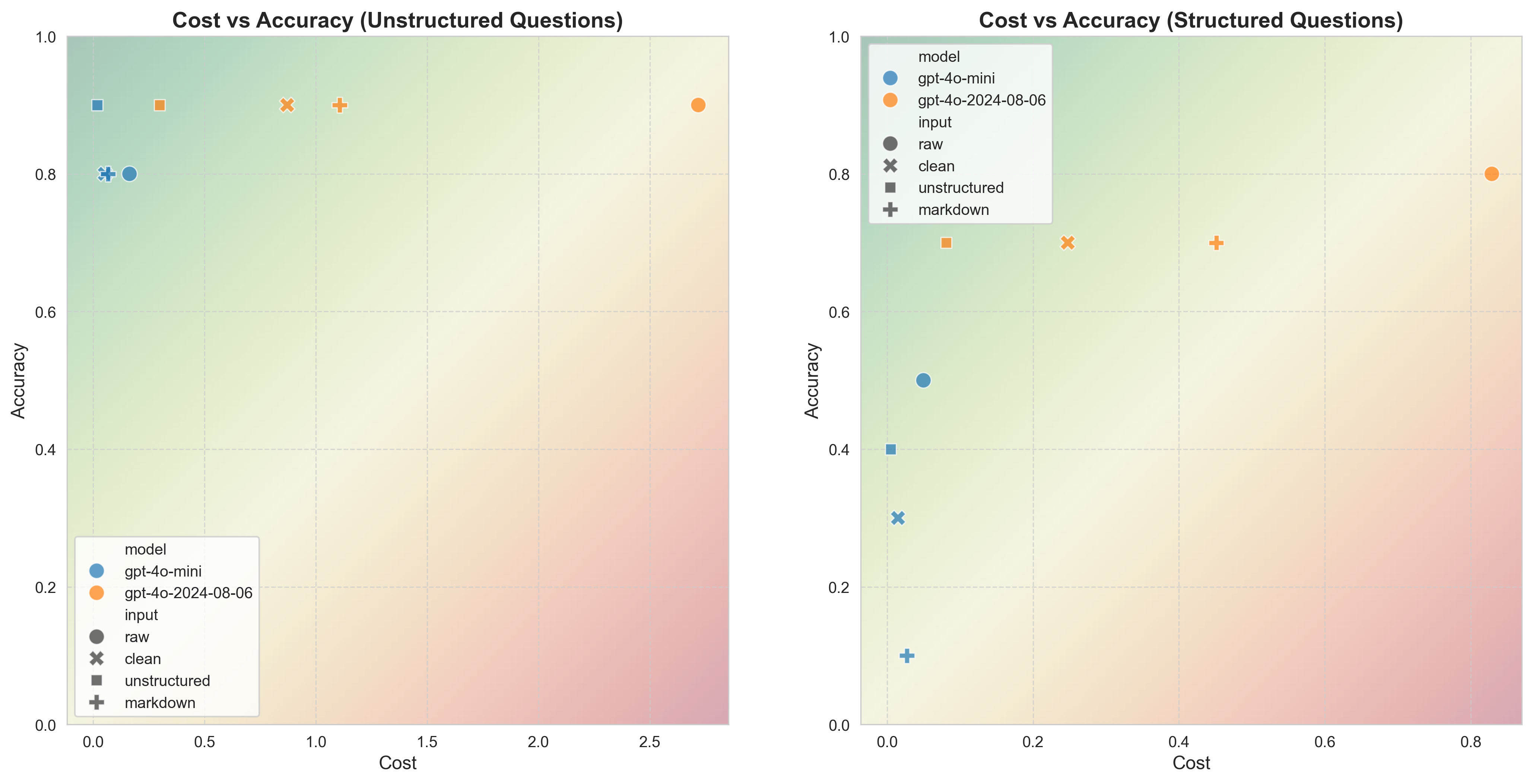
Unstructured
When asking unstructured questions, GPT-4o and its mini version have similar performance and the pre-processing doesn’t make a difference. Since the price gap is big, I recommend using GPT-4o mini for unstructured questions with all the HTML removed to maximize savings.
Structured
Structured questions paint a fairly different scenario: GPT-4o has considerably higher performance than the mini version. However, we see that pre-processing has little to no effect on accuracy. Given the price difference between models, I recommend testing both with a sample of your data and deciding if the accuracy gains justify the steep price increase. In both cases, you can remove all the HTML tags to reduce the price.
Raw results
| model | input | cost | accuracy | question_type |
|---|---|---|---|---|
| gpt-4o-mini | raw | 0.163094 | 0.8 | unstructured |
| gpt-4o-mini | clean | 0.052281 | 0.8 | unstructured |
| gpt-4o-mini | unstructured | 0.017891 | 0.9 | unstructured |
| gpt-4o-mini | markdown | 0.066414 | 0.8 | unstructured |
| gpt-4o-mini | raw | 0.049740 | 0.5 | structured |
| gpt-4o-mini | clean | 0.014858 | 0.3 | structured |
| gpt-4o-mini | unstructured | 0.004851 | 0.4 | structured |
| gpt-4o-mini | markdown | 0.027072 | 0.1 | structured |
| gpt-4o-2024-08-06 | raw | 2.718225 | 0.9 | unstructured |
| gpt-4o-2024-08-06 | clean | 0.871350 | 0.9 | unstructured |
| gpt-4o-2024-08-06 | unstructured | 0.298175 | 0.9 | unstructured |
| gpt-4o-2024-08-06 | markdown | 1.106900 | 0.9 | unstructured |
| gpt-4o-2024-08-06 | raw | 0.829000 | 0.8 | structured |
| gpt-4o-2024-08-06 | clean | 0.247625 | 0.7 | structured |
| gpt-4o-2024-08-06 | unstructured | 0.080850 | 0.7 | structured |
| gpt-4o-2024-08-06 | markdown | 0.451200 | 0.7 | structured |
Final comments
Until GPT-4o becomes cheaper, data extraction tasks require some careful evaluation to avoid breaking the bank. You might be just fine with GPT-4o mini for some cases but GPT-4o’s performance is much better for others, so evaluate for your use case.
Models have inherent randomness but I didn’t include accuracy ranges in the results as that’d involve a higher OpenAI bill (check out my startup, if you become a customer, I’ll be able to justify a higher budget for these experiments!). But I doubt that repeating the experiments would flip the conclusions.
If you want to run the benchmark, here’s the source code. If you want to play with the pre-processing pipelines, try this demo app: https://orange-sea-7185.ploomberapp.io, it’ll allow you to enter a URL and estimate the savings.
If you have questions, ping me on X.
]]>